ASE 2026 / Incident Management / Multi-agent Systems / Self-evolution
OpsAgent
An Evolving Multi-agent System for Incident Management in Microservices
Story
OpsAgent grew out of the questions left behind by TrioXpert. Near the end of that project, I started to notice a limitation that bothered me: although TrioXpert introduced LLM-based reasoning into incident management, its numerical branch still relied on neural models trained over specific datasets. That meant we still had to collect data, fit a model, and hope the learned representation could transfer. For a real operations setting, this felt unsatisfying. A diagnostic system should not become helpless every time the environment changes.
So the first idea behind OpsAgent was much more modest than the final system: build a training-free data processor. I wanted to turn heterogeneous observability data into textual evidence that an LLM could read directly, without training a new model for every dataset. For logs and traces, I extended the textual processing ideas from TrioXpert. Metrics were trickier. They are time-series signals, not sentences. If we wanted to translate them into text, we had to ask a more basic question: what does a metric actually tell us during diagnosis?
The answer was not simply “whether it is abnormal.” For diagnosis, the pattern and magnitude of the anomaly also matter. A sudden spike, a persistent drift, and an oscillating fluctuation may point to different system behaviors. Therefore, OpsAgent first identifies abnormal intervals through an n-sigma rule, extracts the fluctuation magnitude, and then uses a PatternMatcher with a pretrained 1-D CNN to recognize anomaly patterns. In this way, metrics can be converted into compact textual descriptions rather than raw curves. There are other engineering details, such as ranking, cross-pod comparison, and cross-metric comparison, but the core idea is simple: before asking an agent to reason, we should distill observability data into evidence it can actually use.
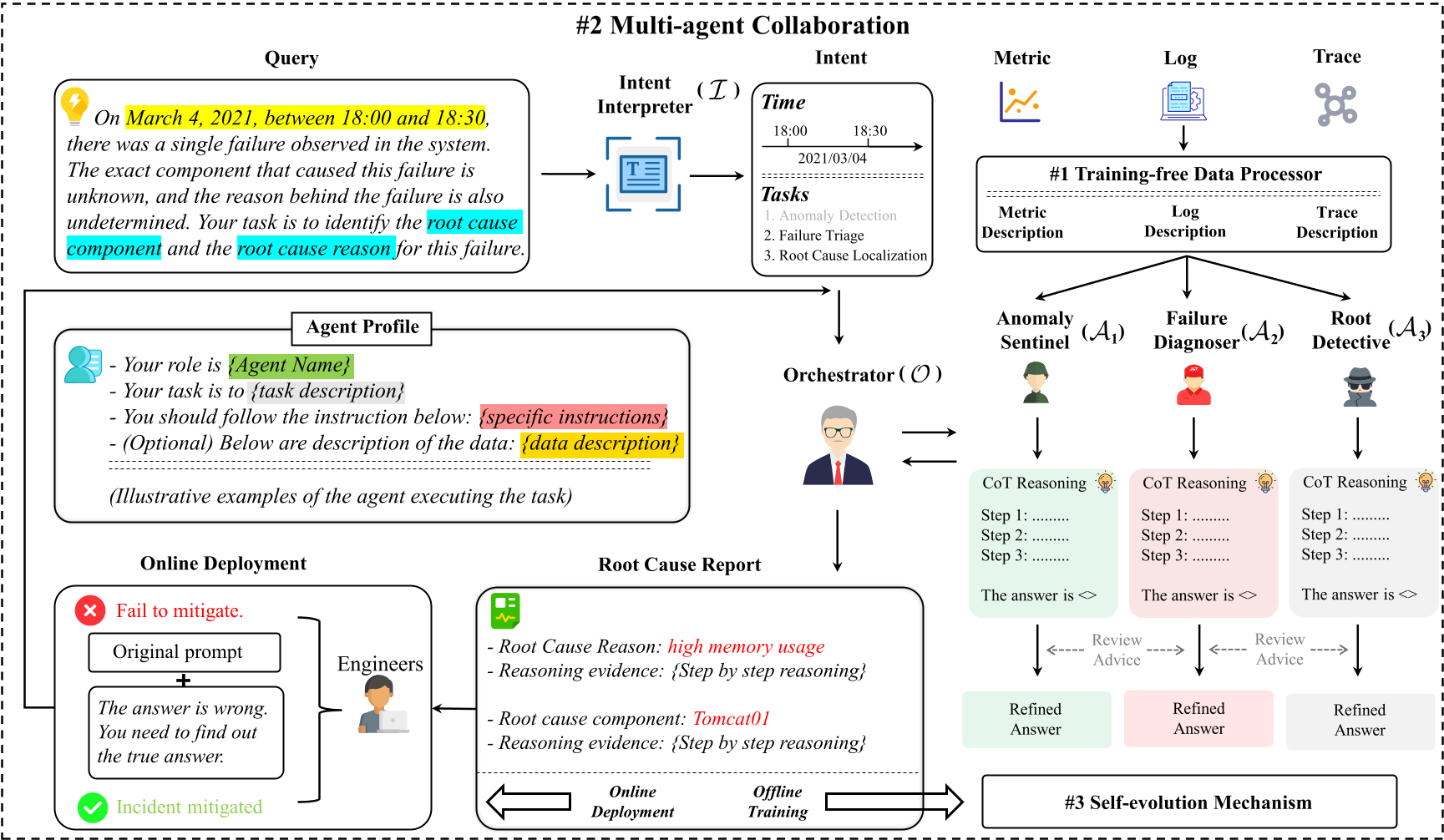
At that point, the processed observability data felt like enriched uranium: dense, refined, and carrying the energy of the whole incident. But enriched uranium does not release its power by simply sitting there. We still needed a way to detonate this metaphorical atomic bomb. For OpsAgent, the multi-agent reasoning framework played that role. Earlier multi-agent systems often felt to me like a loose division of labor: split the data, let several LLMs process their own parts, and merge the answers. I wanted OpsAgent to do more than that. We designed an Orchestrator to coordinate the process, with three task-specific agents responsible for anomaly detection, failure triage, and root cause localization. The preprocessed evidence was the concentrated material; the Orchestrator and specialist agents were the mechanism that turned it into an actual diagnostic chain reaction.
The cross-review mechanism became one of the most important parts of this design. These three tasks observe different dynamics of a microservice system. An anomaly detection agent may notice unusual metric behavior, a failure triage agent may focus on service-level symptoms, and a root cause localization agent may reason about component responsibility. If they work in isolation, each agent can easily miss what another agent sees. By letting them review one another’s reasoning and provide suggestions, OpsAgent turns the three tasks from a pipeline into a collaborative diagnostic conversation.
Even then, the system still felt incomplete to me. We had built a more general processor and a more structured multi-agent framework, but the whole system was still static. Real operations engineers are not static. A new engineer may begin as a rookie, but after seeing enough incidents, reviewing enough mistakes, and accumulating enough cases, they gradually become an expert. I wanted OpsAgent to have a similar sense of growth.
This led to the self-evolution mechanism. We considered two forms of improvement: parametric and non-parametric. Parametric evolution updates the model itself, like committing experience into memory. Non-parametric evolution stores historical trajectories as reusable operational experience, like writing important lessons into a notebook that can be consulted later. The combination of internal learning and external experience made the system feel more realistic to me. OpsAgent was no longer just a one-shot diagnostic framework; it became a loop in which the agent diagnoses, receives feedback, accumulates experience, and gradually improves.
I am especially grateful to Jiamin Jiang, another Ph.D. student whose careful and reliable experimental work was crucial, and to Jingfei Feng for also helping push the experiments forward. Their support made the evaluation much stronger.